At a Glance
OEE increased from around 68% to 82%, improving overall equipment utilization
Unplanned downtime was significantly reduced, enhancing production continuity
Maintenance costs decreased, contributing to operational savings
Fault response time shortened from 4 hours to about 45 minutes
Customer Profile
A chemical company with annual revenue of approximately USD 450 million and 650 employees, primarily engaged in the research, development, and production of fine chemical products. The production facility includes over 300 critical assets such as reactors, centrifuges, drying towers, and compressors, with total equipment asset value exceeding USD 200 million. Equipment management had long relied on paper records and manual experience. Preventive maintenance plan execution rate was below 60%. Unplanned downtime was frequent. Spare parts inventory experienced both shortages and overstock simultaneously.
Equipment Was Silent
The compressor roared, but no one knew how much longer it would last. The reactor operated, but no one knew when it might leak. The pump ran, but no one knew its bearing temperature had already exceeded limits. Equipment worked every day, but equipment did not speak. It did not say I am about to fail. It did not say I need maintenance. It did not say my components are wearing out.
When it could no longer speak, that was when it stopped. Stoppage meant production halt. Production halt meant loss.
This company was once exactly that. Until AMP gave equipment a voice.

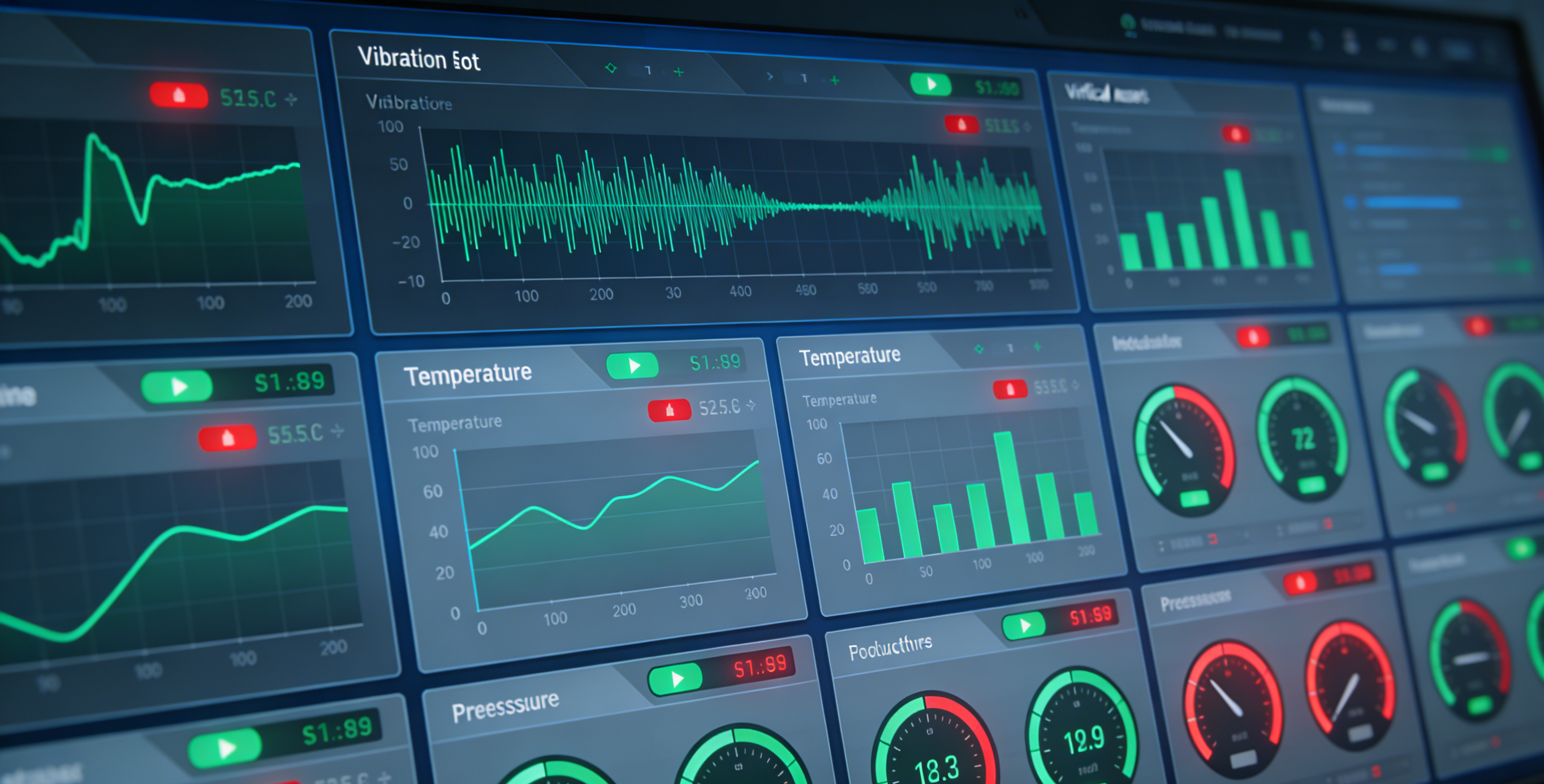
Equipment Status Monitored in Real Time
Previously, equipment condition was assessed by inspection personnel through listening, touching, and observing. Unusual sounds could be heard, high temperatures could be felt, and leaks could be seen. However, these signs were typically noticed only after problems had already occurred. Inspection logs recorded normal conditions while the equipment was already abnormal.
Now, all critical equipment is connected to the system. Vibration, temperature, pressure, current, rotational speed all are collected every second. Data uploads in real time. Threshold alerts trigger automatically. Before equipment fails, the system already indicates that failure is approaching.
Inspections are no longer routine walkthroughs. They are data driven.
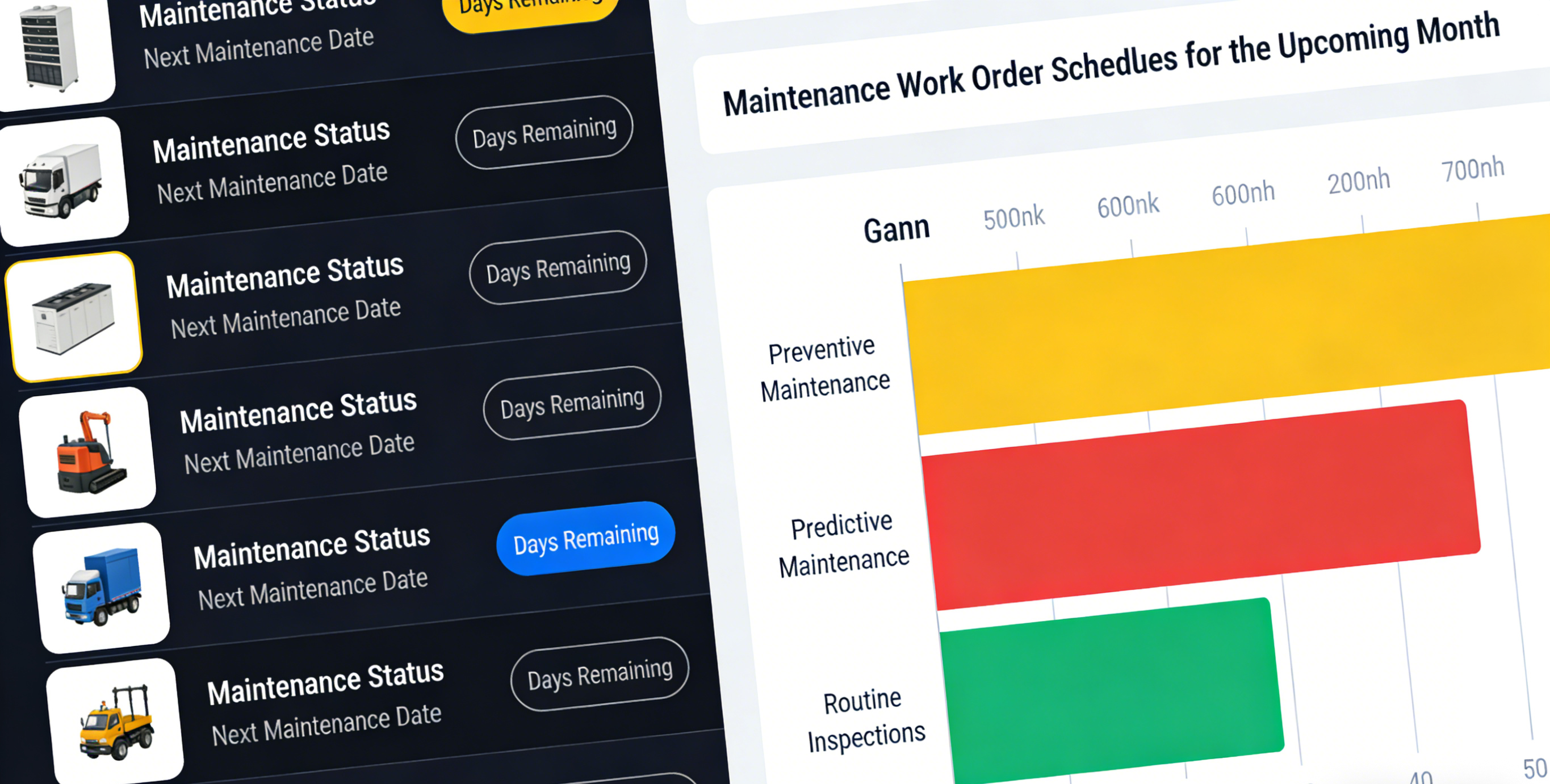
Maintenance Strategy Shifted from Reactive to Proactive
Previously, equipment was repaired only after failure. Fail, repair, fail again, repair again. Maintenance crews were perpetually firefighting. Production perpetually waited. Spare parts were stocked in large quantities, but few were ever used. Components that should have been replaced were not. Components that should not have been replaced were replaced repeatedly.
Now, the system automatically generates maintenance recommendations based on equipment operating data. When operating hours reach thresholds, reminders trigger for preventive maintenance. When vibration anomalies appear, reminders trigger for inspection. When temperature rises, reminders trigger for lubricant replacement. Preventive maintenance plans are automatically scheduled. Work orders are automatically pushed.
Maintenance crews no longer fight fires. They perform scheduled maintenance.
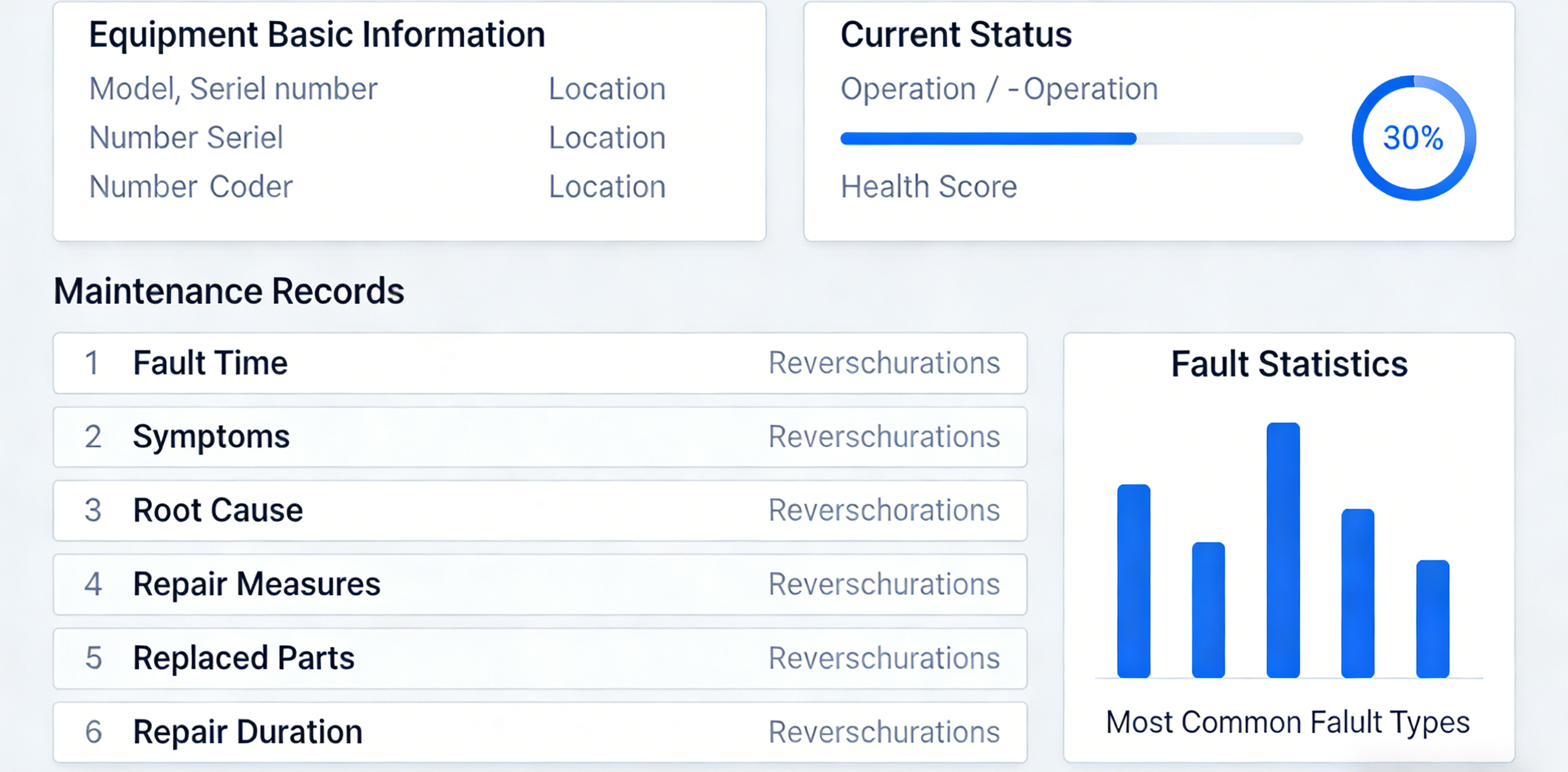
Fault Traceability No Longer Relies on Memory
Previously, when equipment failed, maintenance crews repaired it. After repair, what the problem was, how it was fixed, what parts were replaced all resided in the maintenance crews memory. When the same equipment failed again with a different crew, the investigation started from scratch. Equipment medical records were blank. Every failure was treated as the first occurrence.
Now, every repair is recorded in the system. Fault symptoms, root cause analysis, repair measures, replaced parts, repair duration, repair personnel all are fully traceable. When the same equipment fails again, opening the system reveals the complete history at a glance. When similar equipment experiences the same fault repeatedly, the system automatically alerts, indicating potential design defects or common hidden issues.
Faults are no longer isolated incidents. They are traceable.
Spare Parts Inventory Precisely Matched
Previously, spare parts inventory operated on two disconnected planes. The parts maintenance crews needed were not in stock. The parts in stock were never used by maintenance crews. When shortages occurred, emergency procurement was initiated. When overstock accumulated, no one paid attention. Spare parts tied up capital without providing availability when needed.
Now, the system automatically calculates spare parts requirements based on equipment lists, maintenance schedules, and historical failure data. Which parts should be regularly stocked, which should be strategic spares, which can be procured on demand all are supported by data. When maintenance crews request parts, the system automatically recommends stock locations. When parts are consumed, the system automatically triggers replenishment.
Spare parts decisions are no longer based on intuition. They are calculated.
Customer Testimonial
When equipment failed before, the production line called, maintenance rushed to the site, inspected, then searched for spare parts, then chased procurement if parts were not found. Half a day was gone by the time everything came together. Now the system tells us before equipment fails. It tells us what parts to prepare. Maintenance crews know what to replace before they even reach the site. Equipment downtime is shorter. Output is higher. ——Equipment Manager